
Microsoft’s Phi-2, a 2.7 billion-parameter model, demonstrates remarkable reasoning and language understanding abilities, establishing a new benchmark for performance among base language models with fewer than 13 billion parameters.
Building on the achievements of its forerunners, Phi-1 and Phi-1.5, Phi-2 outperforms models up to 25 times larger, attributed to advancements in model scaling and meticulous training data curation.
Phi-2’s compact dimensions make it a perfect experimental arena for researchers, enabling exploration into mechanistic interpretability, safety enhancements, and fine-tuning experiments across a range of tasks.
Phi-2’s success is based on two crucial aspects:
- Quality Training Data: Microsoft underscores the pivotal role of training data quality in influencing model performance. Phi-2 utilizes “textbook-quality” data, emphasizing synthetic datasets crafted to instill common-sense reasoning and general knowledge. The training corpus is enriched with thoughtfully selected web data, filtered based on educational value and content quality.
- Innovative Scaling Methods: Microsoft employs inventive techniques to scale up Phi-2 from its predecessor, Phi-1.5. The transfer of knowledge from the 1.3 billion-parameter model expedites training convergence, resulting in a notable enhancement in benchmark scores.
Performance evaluation
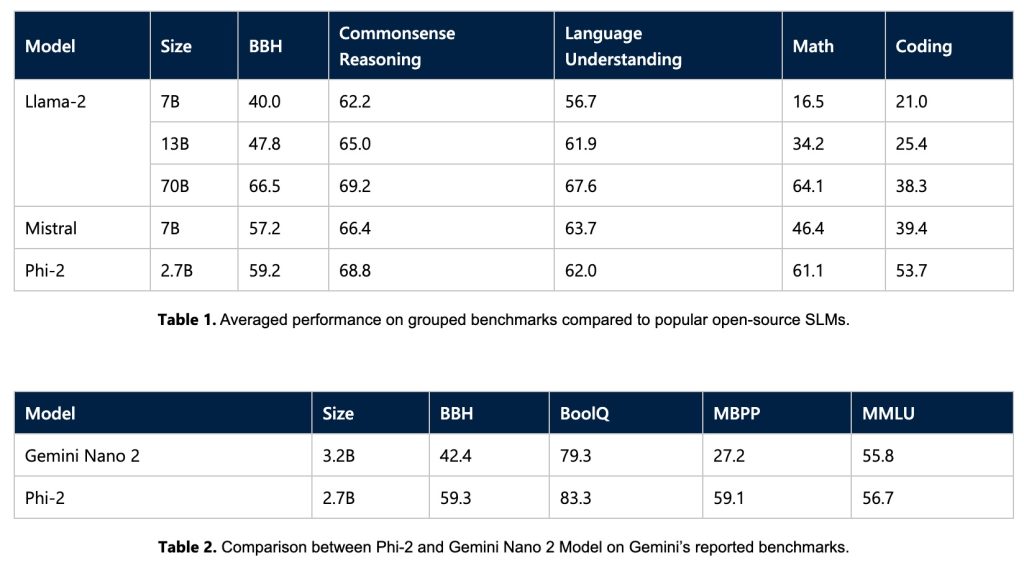
Phi-2 has undergone thorough assessment across diverse benchmarks such as Big Bench Hard, commonsense reasoning, language understanding, math, and coding.
Despite its modest 2.7 billion parameters, Phi-2 surpasses larger models, including Mistral and Llama-2, and achieves comparable or superior performance to Google’s recently revealed Gemini Nano 2:
Outside of traditional benchmarks, Phi-2 demonstrates its prowess in real-world scenarios. Assessments using prompts commonly employed in the research community highlight Phi-2’s ability to solve physics problems and rectify student errors, underscoring its versatility beyond conventional evaluations:

Phi-2 is a Transformer-based model with a next-word prediction objective, trained on 1.4 trillion tokens from synthetic and web datasets. The training process – conducted on 96 A100 GPUs over 14 days – focuses on maintaining a high level of safety and claims to surpass open-source models in terms of toxicity and bias.
With the announcement of Phi-2, Microsoft continues to push the boundaries of what smaller base language models can achieve.
(Image credits: Microsoft Official blog )


