On November 21, Stability AI proudly announces the release of Stable Video Diffusion, their inaugural foundation model for generative video, building upon the image model Stable Diffusion. In this significant stride, Stability AI introduces this state-of-the-art generative AI video model, now accessible in research preview, signifying a notable advancement in their ongoing mission to develop models that cater to diverse user needs.
As part of this research preview, Stability AI has generously shared the code for Stable Video Diffusion on their GitHub repository. Those interested in running the model locally can find the necessary weights on Stability AI’s Hugging Face page. For a deeper dive into the technical capabilities of the model, Stability AI invites enthusiasts to explore the details outlined in their accompanying research paper.
Flexible for Diverse Video Applications
Their video model is super adaptable—it can easily handle different jobs, like putting together multiple views from just one image and getting fine-tuned on datasets with many views. They’ve got exciting plans for more models that will add to and expand on this base, much like the ecosystem that’s grown around stable diffusion.
Additionally, individuals can sign up for the waitlist to gain early access to an upcoming web feature introducing a Text-To-Video interface. This tool highlights the practical applications of Stable Video Diffusion across multiple sectors, including Advertising, Education, Entertainment, and beyond.
High-Performance Competence
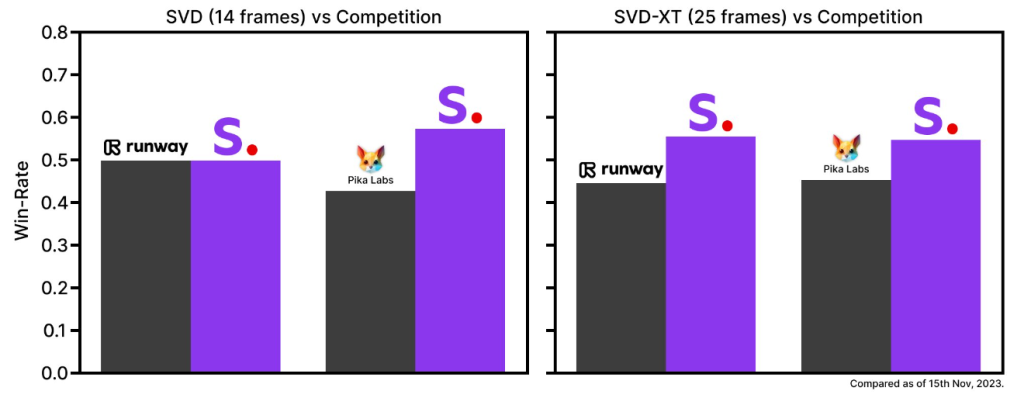
Released as two image-to-video models, Stable Video Diffusion demonstrates its capabilities by generating 14 and 25 frames with customizable frame rates ranging from 3 to 30 frames per second. In their foundational state at the time of release, external evaluations reveal that these models outperform the leading closed models, as confirmed by user preference studies.
Exclusively for Research
As they eagerly incorporate the latest advancements and work on integrating user feedback, it’s emphasized that, at this stage, the model isn’t intended for real-world or commercial applications. Insights and feedback on safety and quality from users are considered crucial for refining the model before its eventual full release. This approach aligns with their past releases in new modalities, and they anticipate sharing the complete release with the user community.